AbstractFileOutputOperator
The abstract file output operator in Apache Apex Malhar library — AbstractFileOutputOperator writes streaming data to files. The main features of this operator are:
- Persisting data to files.
- Automatic rotation of files based on:
a. maximum length of a file.
b. time-based rotation where time is specified using a count of application windows. - Fault-tolerance.
- Compression and encryption of data before it is persisted.
In this tutorial we will cover the details of the basic structure and implementation of all the above features in AbstractFileOutputOperator. Configuration items related to each feature are discussed as they are introduced in the section of that feature.
Persisting data to files
The principal function of this operator is to persist tuples to files efficiently. These files are created under a specific directory on the file system. The relevant configuration item is:
filePath: path specifying the directory where files are written.
Different types of file system that are implementations of org.apache.hadoop.fs.FileSystem are supported. The file system instance which is used for creating streams is constructed from the filePath URI.
FileSystem.newInstance(new Path(filePath).toUri(), new Configuration())
Tuples may belong to different files therefore expensive IO operations like creating multiple output streams, flushing of data to disk, and closing streams are handled carefully.
Ports
input: the input port on which tuples to be persisted are received.
streamsCache
This transient state caches output streams per file in memory. The file to which the data is appended may change with incoming tuples. It will be highly inefficient to keep re-opening streams for a file just because tuples for that file are interleaved with tuples for another file. Therefore, the operator maintains a cache of limited size with open output streams.
streamsCache is of type com.google.common.cache.LoadingCache. A LoadingCache has an attached CacheLoader which is responsible to load value of a key when the key is not present in the cache. Details are explained here- CachesExplained.
The operator constructs this cache in setup(...). It is built with the following configuration items:
- maxOpenFiles: maximum size of the cache. The cache evicts entries that haven't been used recently when the cache size is approaching this limit. Default: 100
- expireStreamAfterAcessMillis: expires streams after the specified duration has passed since the stream was last accessed. Default: value of attribute-
OperatorContext.SPIN_MILLIS.
An important point to note here is that the guava cache does not perform cleanup and evict values asynchronously, that is, instantly after a value expires. Instead, it performs small amounts of maintenance during write operations, or during occasional read operations if writes are rare.
CacheLoader
streamsCache is created with a CacheLoader that opens an FSDataOutputStream for a file which is not in the cache. The output stream is opened in either append or create mode and the basic logic to determine this is explained by the simple diagram below.
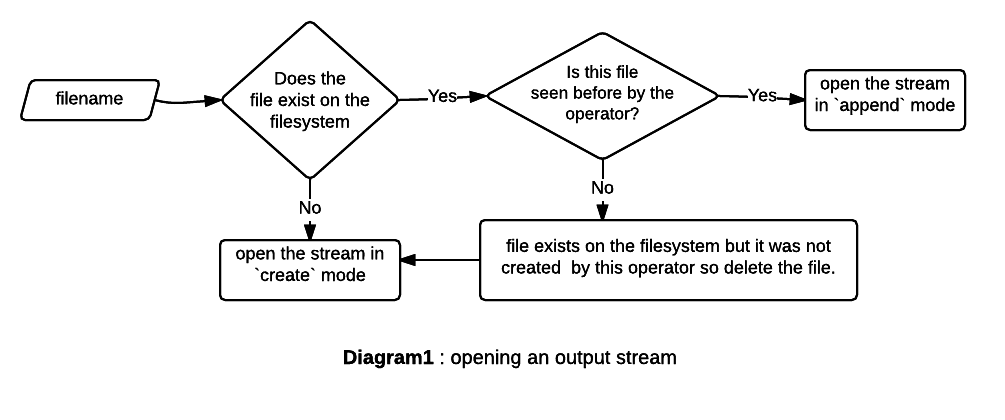
This process gets complicated when fault-tolerance (writing to temporary files) and rotation is added.
Following are few configuration items used for opening the streams:
- replication: specifies the replication factor of the output files. Default:
fs.getDefaultReplication(new Path(filePath)) - filePermission: specifies the permission of the output files. The permission is an octal number similar to that used by the Unix chmod command. Default: 0777
RemovalListener
A Guava cache also allows specification of removal listener which can perform some operation when an entry is removed from the cache. Since streamsCache is of limited size and also has time-based expiry enabled, it is imperative that when a stream is evicted from the cache it is closed properly. Therefore, we attach a removal listener to streamsCache which closes the stream when it is evicted.
setup(OperatorContext context)
During setup the following main tasks are performed:
- FileSystem instance is created.
- The cache of streams is created.
- Files are recovered (see Fault-tolerance section).
- Stray part files are cleaned (see Automatic rotation section).
processTuple(INPUT tuple)
The code snippet below highlights the basic steps of processing a tuple.
protected void processTuple(INPUT tuple)
{
//which file to write to is derived from the tuple.
String fileName = getFileName(tuple);
//streamsCache is queried for the output stream. If the stream is already opened then it is returned immediately otherwise the cache loader creates one.
FilterOutputStream fsOutput = streamsCache.get(fileName).getFilterStream();
byte[] tupleBytes = getBytesForTuple(tuple);
fsOutput.write(tupleBytes);
}
endWindow()
It should be noted that while processing a tuple we do not flush the stream after every write. Since flushing is expensive it is done periodically for all the open streams in the operator's endWindow().
Map<String, FSFilterStreamContext> openStreams = streamsCache.asMap();
for (FSFilterStreamContext streamContext: openStreams.values()) {
...
//this flushes the stream
streamContext.finalizeContext();
...
}
FSFilterStreamContext will be explained with compression and encryption.
teardown()
When any operator in a DAG fails then the application master invokes teardown() for that operator and its downstream operators. In AbstractFileOutputOperator we have a bunch of open streams in the cache and the operator (acting as HDFS client) holds leases for all the corresponding files. It is important to release these leases for clean re-deployment. Therefore, we try to close all the open streams in teardown().
Automatic rotation
In a streaming application where data is being continuously processed, when this output operator is used, data will be continuously written to an output file. The users may want to be able to take the data from time to time to use it, copy it out of Hadoop or do some other processing. Having all the data in a single file makes it difficult as the user needs to keep track of how much data has been read from the file each time so that the same data is not read again. Also users may already have processes and scripts in place that work with full files and not partial data from a file.
To help solve these problems the operator supports creating many smaller files instead of writing to just one big file. Data is written to a file and when some condition is met the file is finalized and data is written to a new file. This is called file rotation. The user can determine when the file gets rotated. Each of these files is called a part file as they contain portion of the data.
Part filename
The filename for a part file is formed by using the original file name and the part number. The part number starts from 0 and is incremented each time a new part file created. The default filename has the format, assuming origfile represents the original filename and partnum represents the part number,
origfile.partnum
This naming scheme can be changed by the user. It can be done so by overriding the following method
protected String getPartFileName(String fileName, int part)
This method is passed the original filename and part number as arguments and should return the part filename.
Mechanisms
The user has a couple of ways to specify when a file gets rotated. First is based on size and second on time. In the first case the files are limited by size and in the second they are rotated by time.
Size Based
With size based rotation the user specifies a size limit. Once the size of the currently file reaches this limit the file is rotated. The size limit can be specified by setting the following property
maxLength
Like any other property this can be set in Java application code or in the property file.
Time Based
In time based rotation user specifies a time interval. This interval is specified as number of application windows. The files are rotated periodically once the specified number of application windows have elapsed. Since the interval is application window based it is not always exactly constant time. The interval can be specified using the following property
rotationWindows
setup(OperatorContext context)
When an operator is being started there may be stray part files and they need to be cleaned up. One common scenario, when these could be present, is in the case of failure, where a node running the operator failed and a previous instance of the operator was killed. This cleanup and other initial processing for the part files happens in the operator setup. The following diagram describes this process
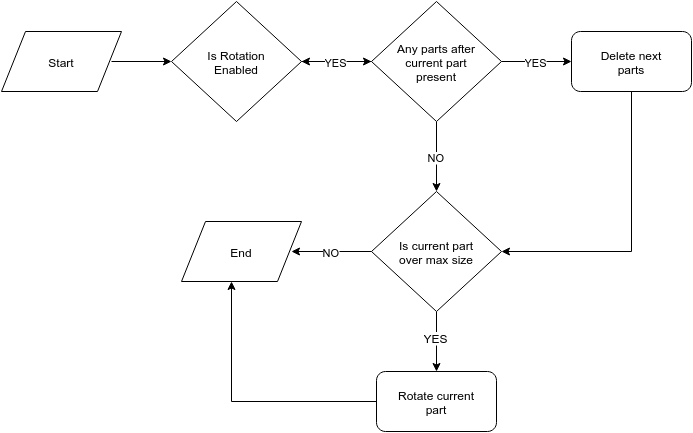
Fault-tolerance
There are two issues that should be addressed in order to make the operator fault-tolerant:
-
The operator flushes data to the filesystem every application window. This implies that after a failure when the operator is re-deployed and tuples of a window are replayed, then duplicate data will be saved to the files. This is handled by recording how much the operator has written to each file every window in a state that is checkpointed and truncating files back to the recovery checkpoint after re-deployment.
-
While writing to HDFS, if the operator gets killed and didn't have the opportunity to close a file, then later when it is redeployed it will attempt to truncate/restore that file. Restoring a file may fail because the lease that the previous process (operator instance before failure) had acquired from namenode to write to a file may still linger and therefore there can be exceptions in acquiring the lease again by the new process (operator instance after failure). This is handled by always writing data to temporary files and renaming these files to actual files when a file is finalized (closed) for writing, that is, we are sure that no more data will be written to it. The relevant configuration item is:
- alwaysWriteToTmp: enables/disables writing to a temporary file. Default: true.
Most of the complexity in the code comes from making this operator fault-tolerant.
Checkpointed states needed for fault-tolerance
-
endOffsets: contains the size of each file as it is being updated by the operator. It helps the operator to restore a file during recovery in operatorsetup(...)and is also used while loading a stream to find out if the operator has seen a file before. -
fileNameToTmpName: contains the name of the temporary file per actual file. It is needed because the name of a temporary file is random. They are named based on the timestamp when the stream is created. During recovery the operator needs to know the temp file which it was writing to and if it needs restoration then it creates a new temp file and updates this mapping. -
finalizedFiles: contains set of files which were requested to be finalized per window id. -
finalizedPart: contains the latestpartof each file which was requested to be finalized.
The use of finalizedFiles and finalizedPart are explained in detail under requestFinalize(...) method.
Recovering files
When the operator is re-deployed, it checks in its setup(...) method if the state of a file which it has seen before the failure is consistent with the file's state on the file system, that is, the size of the file on the file system should match the size in the endOffsets. When it doesn't the operator truncates the file.
For example, let's say the operator wrote 100 bytes to test1.txt by the end of window 10. It wrote another 20 bytes by the end of window 12 but failed in window 13. When the operator gets re-deployed it is restored with window 10 (recovery checkpoint) state. In the previous run, by the end of window 10, the size of file on the filesystem was 100 bytes but now it is 120 bytes. Tuples for windows 11 and 12 are going to be replayed. Therefore, in order to avoid writing duplicates to test1.txt, the operator truncates the file to 100 bytes (size at the end of window 10) discarding the last 20 bytes.
requestFinalize(String fileName)
When the operator is always writing to temporary files (in order to avoid HDFS Lease exceptions), then it is necessary to rename the temporary files to the actual files once it has been determined that the files are closed. This is refered to as finalization of files and the method allows the user code to specify when a file is ready for finalization.
In this method, the requested file (or in the case of rotation — all the file parts including the latest open part which have not yet been requested for finalization) are registered for finalization. Registration is basically adding the file names to finalizedFiles state and updating finalizedPart.
The process of finalization of all the files which were requested till the window w is deferred till window w is committed. This is because until a window is committed it can be replayed after a failure which means that a file can be open for writing even after it was requested for finalization.
When rotation is enabled, part files as and when they get completed are requested for finalization. However, when rotation is not enabled user code needs to invoke this method as the knowledge that when a file is closed is unknown to this abstract operator.